
 设计改造篇-多租户隔离方案
设计改造篇-多租户隔离方案
# 一、部署架构的选择?
从性能以及对分片数据库进行管理和运维的场景的考虑,我们采用了混合部署架构,通过混合使用 ShardingSphere‐JDBC 和ShardingSphere‐Proxy,并采用注册中心管理配置
生产环境业务比较复杂,暂时使用Standalone部署方式
# 二、租户隔离如何实现?
# 2.1、租户隔离的实现?
基本规则如下:
1、defaultDataSources: 默认数据源,对应未分库前的数据源,用于过渡
2、shardingDataSources:分片数据源,对应分库后的数据源,指定的一批用户会通过取模方式,分散到固定的若干个schema
3、tenIdToDataSources: 独立数据源,若用户有数据完全隔离的需求,可以在此进行配置,用户单独一个schema
配置如下:
#决定租户id路由到哪个数据源,优先级 tenIdToDataSources > shardingDataSources > defaultDataSources
sharding:
#默认的多租户数据源,考虑默认库压力可能会比较大,可分为任意大小的数据源
defaultDataSources:
- "readwrite_ds_0"
#租户和数据源的配置,取模路由到某个数据源,规则如下:
#若tenId在0到100范围内,3003622到9999999范围内,tenId=10001
#则通过数据源数量取模使用某个数据源 , ds = datasources.get(tenId%datasources.size())
shardingDataSources:
tenIds:
- [0,100]
- [2900005]
- [3003622,99999999]
datasources:
- "readwrite_ds_0"
#租户和数据源的配置,指定路由到某个数据源,规则如下:
#若tenId=2900005
#则直接使用readwrite_ds_1数据源
tenIdToDataSources:
2900005: readwrite_ds_1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 2.2、分片策略的选择?
# 2.2.1、shardingsphere-jdbc
在shardingsphere-jdbc层选择了hint分片策略和标准分片策略,因为租户隔离的分片字段非SQL决定,而是由租户id决定的,因此整体使用hint分片策略。另外考虑到旧系统自研了分表功能以及后期部分表数据量过大的情况,为了做兼容,部分表需要使用标准分片策略
hint分片算法
在分片算法中,实现了全库路由、多库路由、单库路由的功能
全库路由:部分业务场景需要查询所有的库,比如支付第三方回调
多库路由:存在上游同时查询多个下游的数据,比如ten_id in(1,2,3);
@Override
public Collection<String> doSharding(Collection<String> collection, HintShardingValue<String> hintShardingValue) {
String hintValue = hintShardingValue.getValues().iterator().next();
// 全库路由
if (HintManagerConstant.ROUTE_ALL_DATA_SOURCE.equals(hintValue)) {
return collection;
}
Set<String> result = new HashSet<>();
// 多库路由
if (hintValue.startsWith(HintManagerConstant.PREFIX_MUL_DATA_SOURCE)) {
hintValue = hintValue.replace(HintManagerConstant.PREFIX_MUL_DATA_SOURCE, "");
Arrays.asList(hintValue.split(HintManagerConstant.SPLIT_COMMA)).stream().map(Integer::valueOf).forEach(tenId -> {
result.add(ShardingCidContext.getInstance().getDatasourceByCid(tenId));
});
return result;
}
// 单库路由
result.add(ShardingCidContext.getInstance().getDatasourceByCid(Integer.valueOf(hintValue)));
return result;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
标准分片算法
@Override public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Integer> shardingValue) { if (availableTargetNames.size() == 1) { // 如果tenId在tenIdToDataSources配置中或者shardingDataSources配置中,不分表 return shardingValue.getLogicTableName(); } String tenId = shardingValue.getValue().toString(); int index = Integer.valueOf(tenId) % (availableTargetNames.size()); return availableTargetNames.toArray()[index] + ""; }1
2
3
4
5
6
7
8
9
10
# 2.2.2、shardingsphere-proxy
在shardingsphere-proxy层选择了标准分片策略,考虑到两点:
1、数据迁移的过程中,使用到了shardingsphere-proxy。
2、运维人员执行SQL时,不用太关心当前执行的SQL需要路由到哪个库或者哪个表
/* SHARDINGSPHERE_HINT: t_order.SHARDING_DATABASE_VALUE=1, t_order.SHARDING_TABLE_
VALUE=1 */ SELECT * FROM t_order;
2
# 2.3、SQL审计
实现SQL审计功能,为避免全表路由,在shardingsphere-jdbc层对没有使用hint的,一律拦截,抛出异常
public void check(SQLStatementContext<?> sqlStatementContext, List<Object> params, Grantee grantee, ShardingSphereRuleMetaData globalRuleMetaData, ShardingSphereDatabase database) {
if (sqlStatementContext.getSqlStatement() instanceof DMLStatement) {
ShardingRule rule = database.getRuleMetaData().getSingleRule(ShardingRule.class);
if (!rule.isAllBroadcastTables(sqlStatementContext.getTablesContext().getTableNames())) {
Objects.requireNonNull(rule);
boolean audited = HintManager.isInstantiated() &&
(HintManager.getDatabaseShardingValues().size() > 0 || HintManager.getDataSourceName().isPresent());
// 1、分片表shardingTable但是未指定路由信息,则抛出异常
if (!audited && sqlStatementContext.getTablesContext().getTableNames().stream().anyMatch(rule::isShardingTable)) {
ShardingSpherePreconditions.checkState(!(new ShardingConditionEngine(globalRuleMetaData, database, rule)).createShardingConditions(sqlStatementContext, params).isEmpty(), () -> {
return new SQLAuditException("分库分表审计不通过,请务必解决!");
});
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 三、数据迁移方案选择?
分库分表后,必然会做数据迁移,做数据迁移,并结合公司的业务,我们需要考虑以下三点:
1、全量迁移(行级别,某个租户id)
2、增量迁移(行级别)
3、一致性校验
最终我们选择使用Datax,做半停服迁移
# 3.1、半停服迁移 Datax
低峰时期,对需要迁移的租户发布停服公告,让该租户无法登录系统,这样就没有数据写入,能够保证迁移工作的正常进行,没有一致性的问题
停服迁移是最常见的一种方案了,一般如下流程: 1.预估停服时间,发布停服公告
2.停服,通过事先做好的数据迁移工具,按照新的分片规则,进行迁移
3.修改分片规则
4.启动服务
# 3.2、双写
开发工作量大
# 3.3、不停服迁移,全量迁移+增量迁移+一致性校验
shardingsphere5.2.1版本当前只支持库和表级别的迁移,不支持行级别(输入条件)迁移,检查了最新版本5.3.0也不支持行级别迁移,考虑改动其源码,DistSQL研究改造,涉及模块多,改造成本大
- 库级别迁移(所有表)
- 表级别迁移(任意多个表)
- 迁移数据一致性校验
MIGRATE TABLE ds_0.t_order INTO t_order;
1.开启job: MigrateTableUpdater.executeUpdate,写入zk job信息
2.触发:ChangedJobConfigurationDispatcher处理Job信息
3.生成SQL: AbstractPipelineSQLBuilder.buildDivisibleInventoryDumpSQL
SELECT * FROM t_order WHERE order_id>=? AND order_id<=? ORDER BY order_id ASC LIMIT ?
改造方式:
1.使用/**/方式做扩展 参考:SQLHintUtils
2.使用 migrate-table-without-schema-target-db migrate distsql定制,MigrateTableStatement
2
3
4
5
6
7
8
9
# 四、改造FAQ
# 4.1、Shardingsphere兼容性问题,在Mybatis使用 like "%"#{loginName}"%"'查询
在Mybatis中使用如下查询方式,在shardingsphere中查询会报错
SELECT u.id AS id,
u.login_name AS loginName,
u.name AS name
FROM t_user u
<if test="phone != ''" >
and u.phone like "%"#{phone}"%"
</if>
<if test="loginName != ''" >
and u.login_name like "%"#{loginName}"%"
</if>
2
3
4
5
6
7
8
9
10
问题原因:
上述的查询方式,最后生成的SQL语句为 like "%"'15276'"%",在sharingsphere中暂不支持
解决办法:
1、在MySQL中替换为 CONCAT 函数 like CONCAT('%', #{loginName}, '%')
2、在 java 代码中传参的时候直接写上,param.setLoginName("%CD%"); 然后 mapper 里面直接写 #{} 就可以了
<if test="loginName != ''" >
and u.login_name like "%"#{loginName}"%"
</if>
2
3
# 4.2、使用Mybatis插入广播表数据时,获取插入的自增主键Id,出现如下报错
org.apache.ibatis.executor.ExecutorException: Too many keys are generated. There are only 1 target objects. You either specified a wrong 'keyProperty' or encountered a driver bug like #1523.
at org.apache.ibatis.executor.keygen.Jdbc3KeyGenerator.assignKeysToParam(Jdbc3KeyGenerator.java:121) ~[mybatis-3.5.6.jar:3.5.6]
at org.apache.ibatis.executor.keygen.Jdbc3KeyGenerator.assignKeys(Jdbc3KeyGenerator.java:104) ~[mybatis-3.5.6.jar:3.5.6]
at org.apache.ibatis.executor.keygen.Jdbc3KeyGenerator.processBatch(Jdbc3KeyGenerator.java:85) ~[mybatis-3.5.6.jar:3.5.6]
at org.apache.ibatis.executor.keygen.Jdbc3KeyGenerator.processAfter(Jdbc3KeyGenerator.java:71) ~[mybatis-3.5.6.jar:3.5.6]
at org.apache.ibatis.executor.statement.PreparedStatementHandler.update(PreparedStatementHandler.java:51) ~[mybatis-3.5.6.jar:3.5.6]
at org.apache.ibatis.executor.statement.RoutingStatementHandler.update(RoutingStatementHandler.java:74) ~[mybatis-3.5.6.jar:3.5.6]
2
3
4
5
6
7
问题原因:
在mybatis 3.5.6 + shardingsphere5.2.1中,插入广播表记录时,ShardingspherePrepapredStatement.getGeneratedKeys方法返回的多个ResultSet,导致 mybatis 的KeyGenerator 获取生成的主键值时出现异常
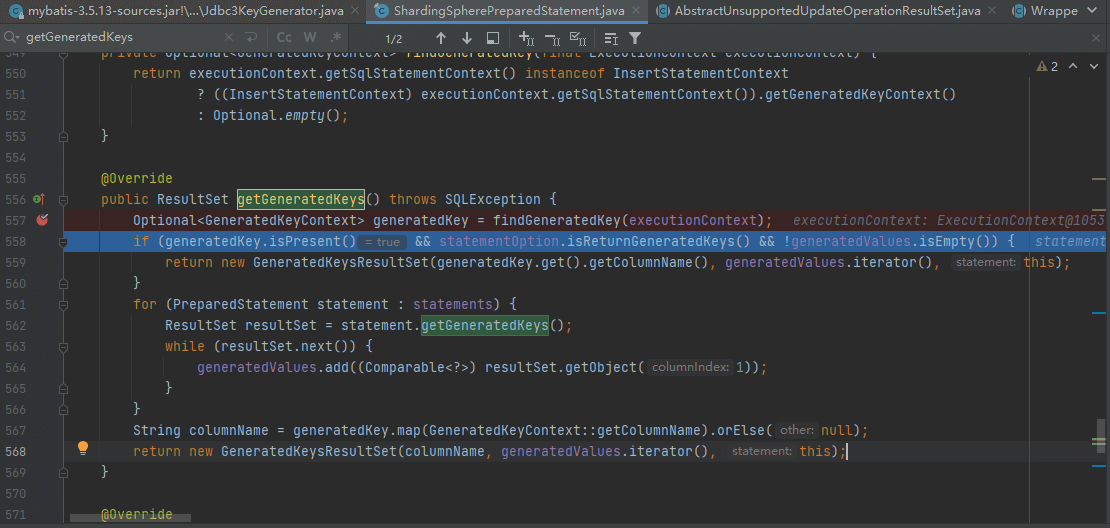
在Mybatis3.5.6版本中Jdbc3KeyGenerator会先循环ResultSet,依次给对象设置主键值,如果对象不存在,直接抛出异常
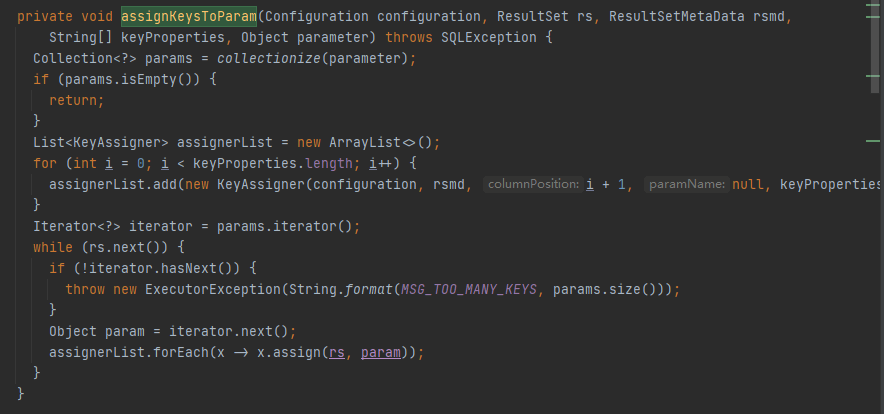
在Mybatis3.5.0版本中Jdbc3KeyGenerator会先循环对象,依次从ResultSet中获取主键值,如果对象不存在,直接break
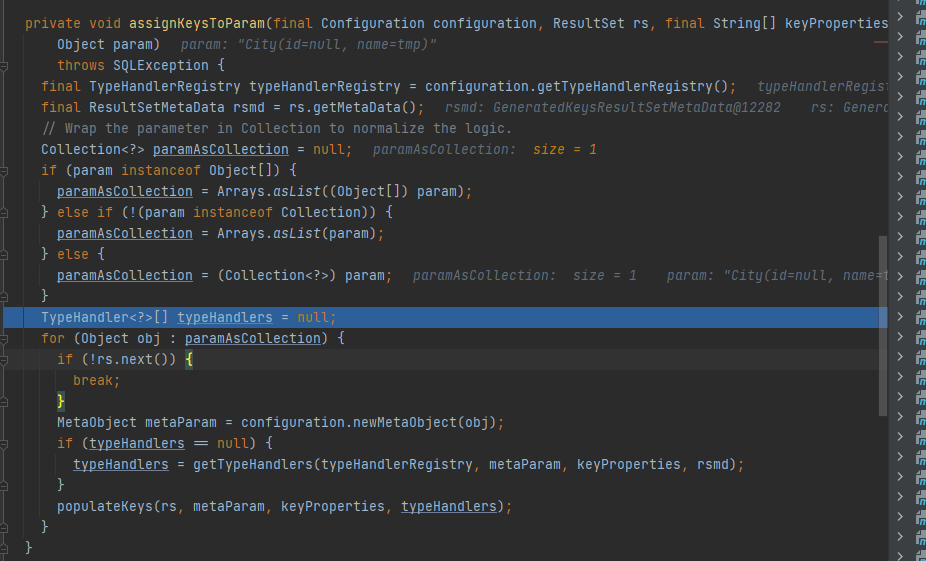
解决方式:
将mybatis版本降为3.5.0或使用雪花id
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.0</version>
</dependency>
2
3
4
5
MyBatis中的KeyGenerator是什么?
SelectKeyGenerator和Jdbc3KeyGenerator都是 MyBatis 提供的用于获取生成的主键值的方法,但它们的实现方式不同。
SelectKeyGenerator使用了 SQL 查询来获取生成的主键值。在执行插入语句之前,会先执行一条查询语句,以获取当前数据库中自增字段或序列的值,并将其赋值给实体类对象中的主键属性。因此,使用SelectKeyGenerator可以确保得到正确的主键值,无论是自增字段还是序列。而
Jdbc3KeyGenerator则是基于 JDBC 3.0 规范提供的PreparedStatement.getGeneratedKeys()方法实现的。在执行插入语句之后,可以通过该方法获取到生成的主键值,并将其赋值给实体类对象中的主键属性。需要注意的是,Jdbc3KeyGenerator只能用于支持 JDBC 3.0 规范的数据库,且只能获取自动生成的主键字段的值。对于非自动生成的主键或序列,无法使用Jdbc3KeyGenerator获取其值。因此,如果您需要获取自动生成的主键值,建议使用
SelectKeyGenerator;如果您需要跨多种数据库平台兼容性更好的方式,可以考虑使用Jdbc3KeyGenerator。如果您的项目已经使用了 Spring Boot + MyBatis-Plus,可以直接使用@TableId(type = IdType.AUTO)注解,它会根据不同的数据库自动选择合适的主键生成方式,包括SelectKeyGenerator和Jdbc3KeyGenerator。
# 4.3、多线程并发插入广播表时,广播表主键Id可能返回不准确问题
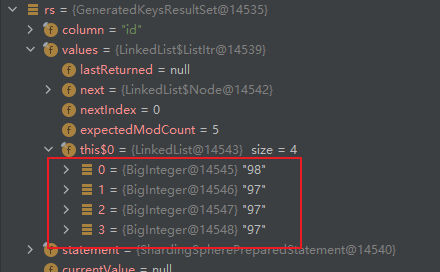
如上图所示,在并发情况下,插入一个广播表,返回了不同的id
问题原因:
多线程并发影响数据库自增
解决方案:
使用雪花id
# 4.4、The table inserted and the table selected must be the same or bind tables.
当执行下面的语句时没出现上述错误
INSERT INTO `t_user_role`(
user_id,
role_id,
create_time,
update_time
)
SELECT *
FROM (
SELECT ? AS user_id,
role.id AS role_id,
NOW() AS create_time,
NOW() AS update_time
FROM t_role `role`
WHERE id = ?
) childUserRole
WHERE NOT EXISTS (
SELECT 1
FROM t_user_role userRole
WHERE userRole.role_id = childUserRole.role_id
AND userRole.user_id = childUserRole.user_id
);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
问题原因:
shardingsphere有校验,在insert .... select语句中,insert插入的表和select查询的表必须是同一张表或者绑定表
解决方式:
在配置文件中配置绑定表即可
bindingTables:
- t_role,t_user_role
2
# 4.5、 连接代理库,执行下面SQL报错,Can not support DML operation with multiple tables
SQL 错误 [20045] [0A000]: Can not support DML operation with multiple tables [t_order, t_order_dt, scm_goods_stored].
update
t_order_dt odt
inner join t_order o
on odt.orders_sn = o.orders_sn
set
odt.out_before_number = IFNULL(storeOut.number, 0),
odt.in_before_number = IFNULL(storeIn.number, 0)
where odt.orders_sn = '123456';
2
3
4
5
6
7
8
问题原因:
多表不支持DML操作,shardingsphere针对DML语句进行如下校验
protected void validateMultipleTable(final ShardingRule shardingRule, final SQLStatementContext<T> sqlStatementContext) {
Collection<String> tableNames = sqlStatementContext.getTablesContext().getTableNames();
boolean isAllShardingTables = shardingRule.isAllShardingTables(tableNames) && (1 == tableNames.size() || shardingRule.isAllBindingTables(tableNames));
boolean isAllBroadcastTables = shardingRule.isAllBroadcastTables(tableNames);
boolean isAllSingleTables = !shardingRule.tableRuleExists(tableNames);
if (!(isAllShardingTables || isAllBroadcastTables || isAllSingleTables)) {
throw new DMLWithMultipleShardingTablesException(tableNames);
}
}
2
3
4
5
6
7
8
9
解决方法:
代码改造或者根据情况配置成绑定表
备注:此处不建议配置为绑定表,业务关联不大
# 4.6、微服务接入shardingsphere后,启动出现报错
Caused by: java.lang.ClassNotFoundException: org.apache.curator.connection.StandardConnectionHandlingPolicy
at java.net.URLClassLoader.findClass(URLClassLoader.java:387)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:355)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
... 79 common frames omitted
2
3
4
5
6
问题原因:
项目之间依赖问题,使用到了下面的几个依赖的低版本4.0.1,
解决方法:
引入shardingsphere 5.2.1依赖的几个文件即可
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>5.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-client</artifactId>
<version>5.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>5.1.0</version>
</dependency>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 4.7、数据库配置了默认的分片策略,但是不生效?
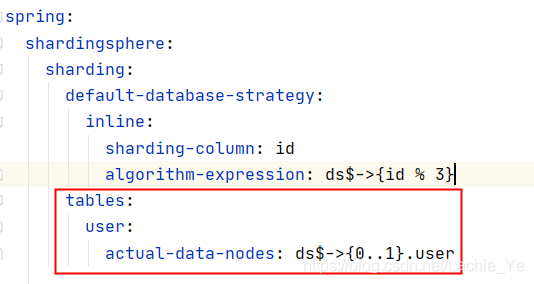
配置了数据库默认分片策略,并没有执行该分片策略
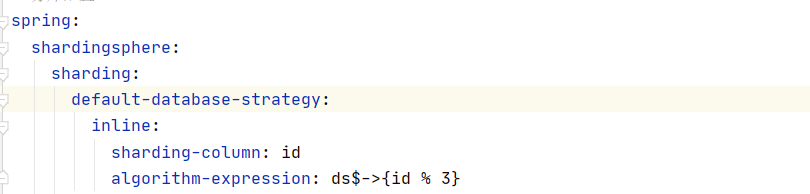
问题原因:
理解有误,该配置项是针对已配置表规则,但是未配置分片策略在当前版本是单表
解决方案:配置表策略即可,不用给表配置分片策略
参考:ShardingShpere配置default-database-strategy或default-table-strategy失效原因 (opens new window)
# 五、上线FAQ
# 5.1、数据库账号配置为只读账号,但是仍然插入修改数据的问题
上线过程中,为了避免数据的不一致,在我们进行数据迁移前,将数据库账号配置为只读,但是部分用户仍然可以插入和修改数据
问题原因:
对于数据库账号配置为只读前的产生连接并不会生效
解决办法:
1、数据库账号设置成只读账号后,重启服务
2、kill 用户的所有session
# 5.2、上下游服务未切换sharding数据源问题
对于此次上线,只考虑到了当前系统切换sharding数据源,未考虑到上下游服务切换sharding数据源