亿级流量系统JVM实战
亿级流量系统JVM实战
# 亿级流量系统JVM实战
# 一、亿级流量快递系统如何设置JVM参数(ParNew+CMS)
大型快递系统的后端现在一般都是拆分为多个子系统部署的,比如,基础资料系统,客户平台系统,操作平台系统,网点经营系统,财务结算系统等等。
我们这里的话就以比较核心的网点经营系统为例
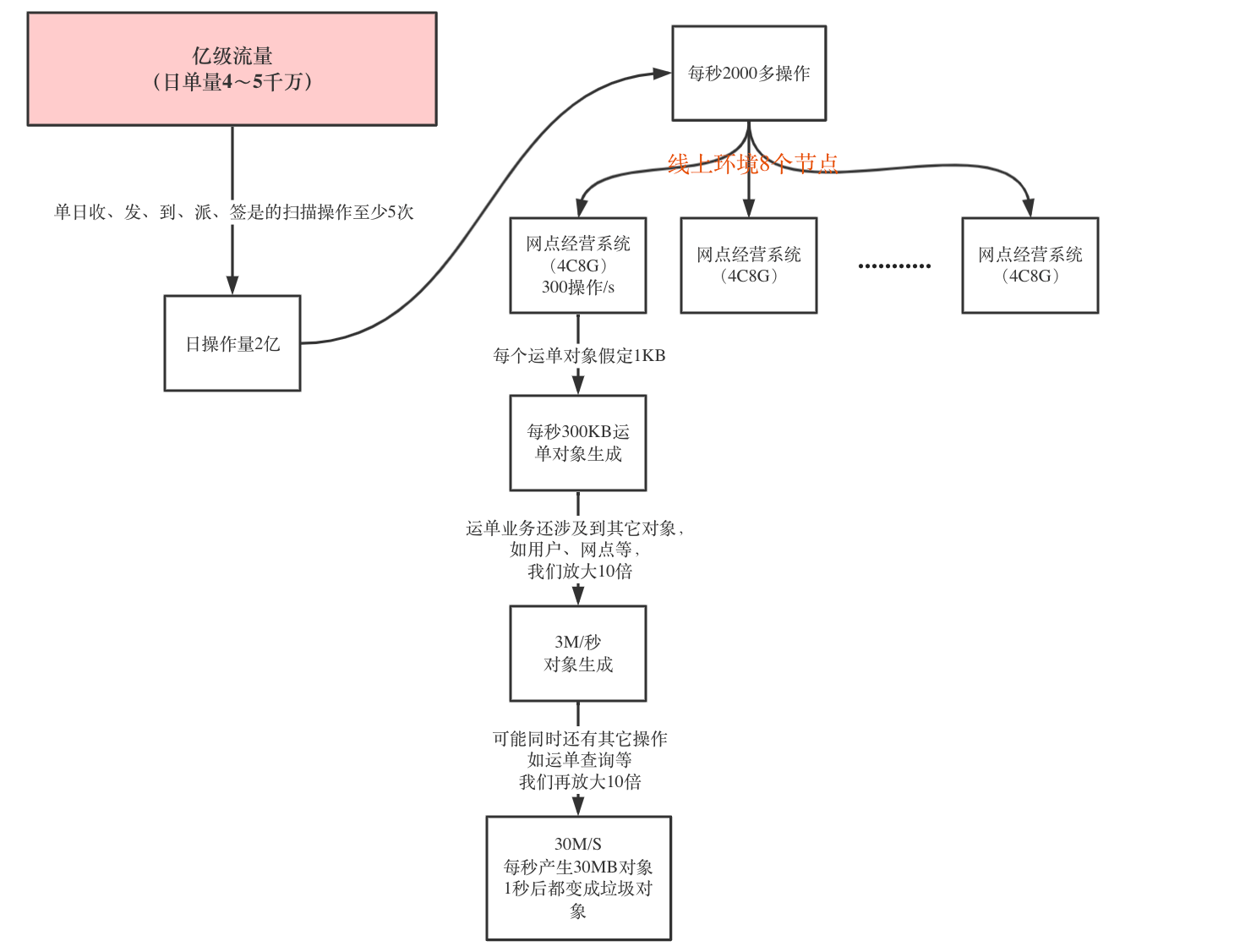
# 第一步:系统流量评估--首先我们要对系统流量进行一个大致评估
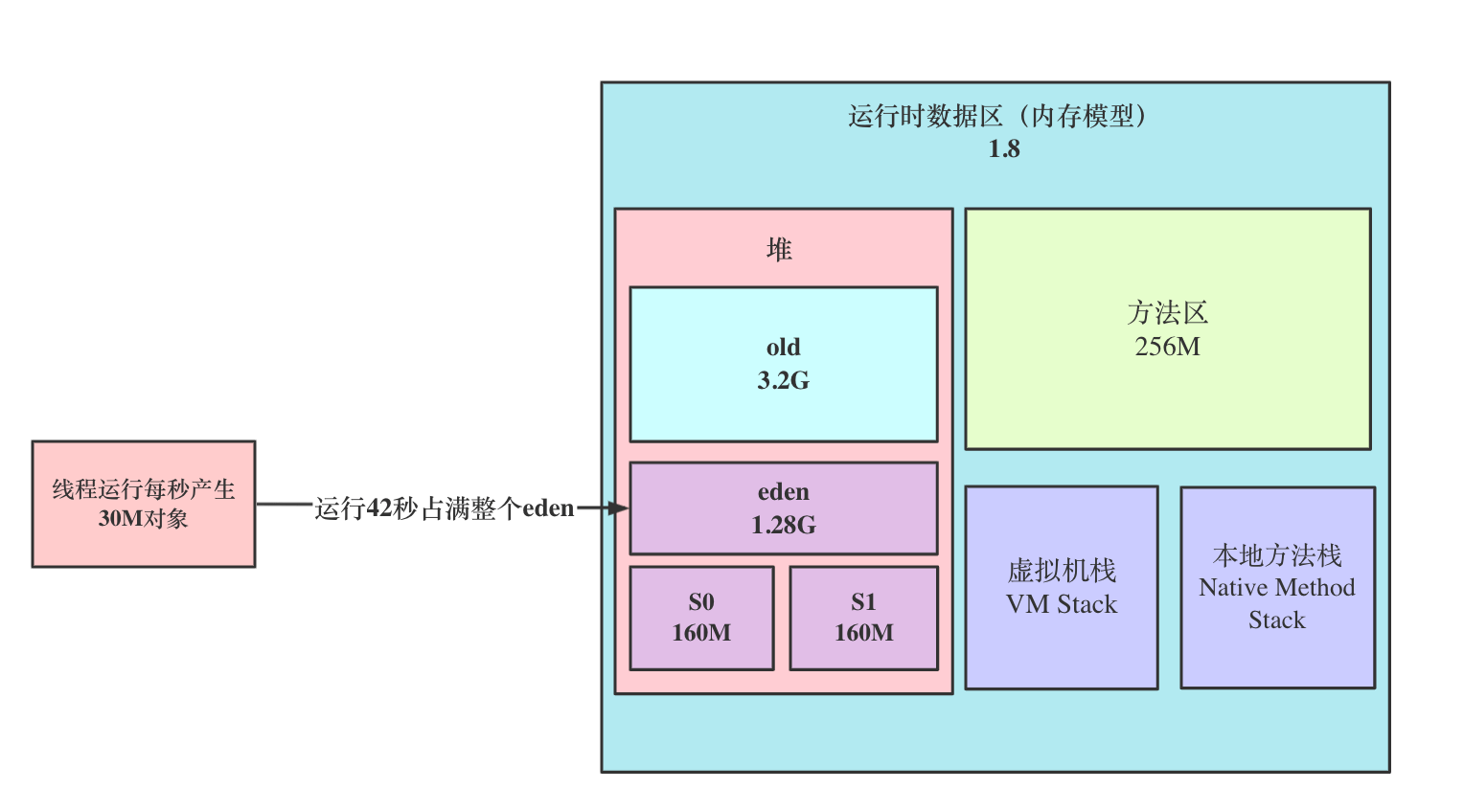
# 第二步:JVM模型评估--对JVM内存进行评估
对于4C8G的机器,我们一般是分配4G内存给JVM,目前我们线上环境是分配60%的内存,也就是4.8G给JVM,JVM参数配置如下:
-XX:MaxRAMPercentage=60.0 -XX:InitialRAMPercentage=60.0 -XX:MinRAMPercentage=60.0 -XX:NewRatio=2 -Xss512k -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=512M
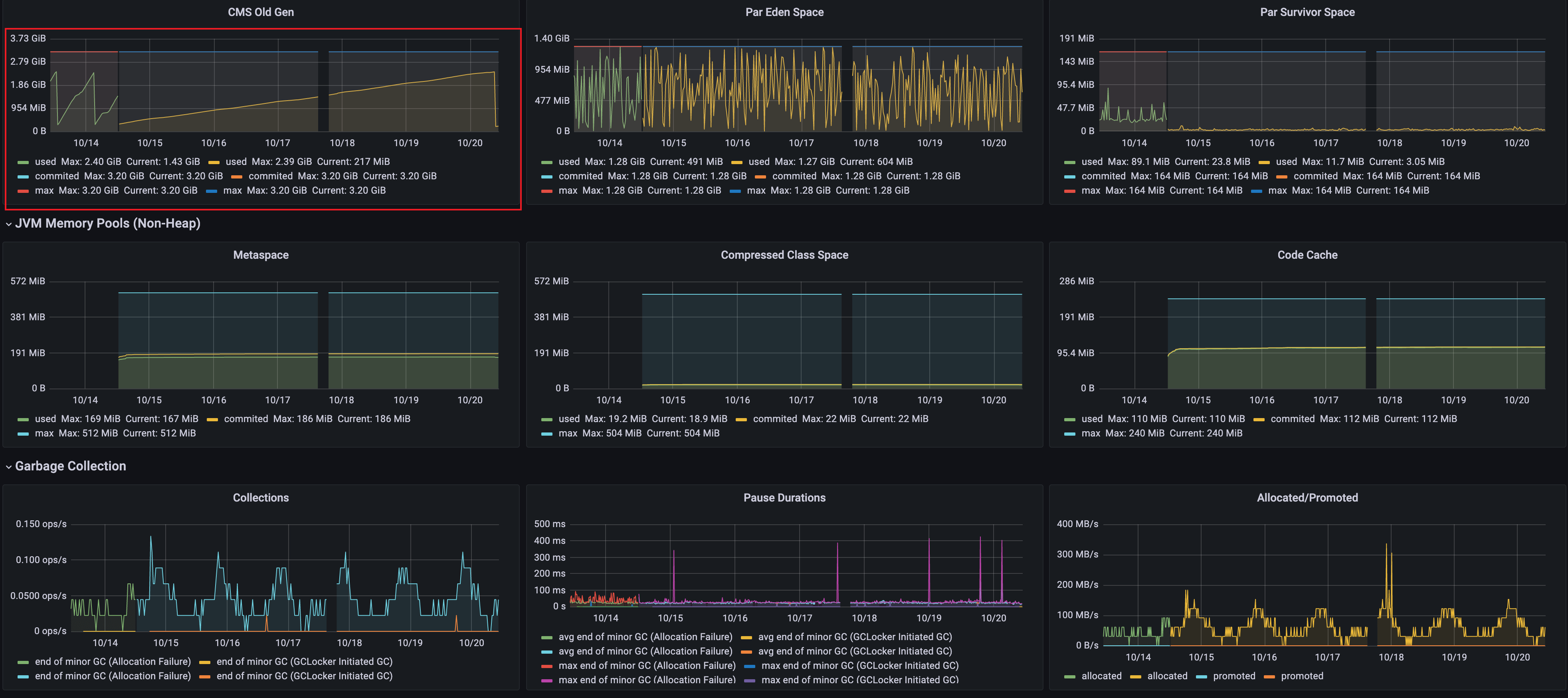
# 第三步:JVM运行情况评估
通过第一步和第二步的分析,我们知道了每秒产生30M对象,大概运行42秒占满整个Eden区,随后进行一次Minor GC,存活的对象会进入Survivor区,多次Minor GC后,满足一定条件,会进入老年代。整个过程遵从对象内存分配的规则,例如大对象直接进入老年代、对象动态年龄判断机制、长期存活的对象进入老年代、老年代空间分配担保机制等等
总而言之:尽可能让对象都在新生代里分配和回收,同时给系统足够的内存,避免频繁对新生代进行垃圾回收,尽量别让太多对象频繁进入老年代,避免频繁对老年代进行垃圾回收
# 第四步:调优实践落地
我们把JVM调优参数分为三部分:
-XX:MaxRAMPercentage=60.0 -XX:InitialRAMPercentage=60.0 -XX:MinRAMPercentage=60.0 -XX:NewRatio=2 -Xss512k -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=512M
垃圾收集器
对于JDK8默认的垃圾回收器是-XX:+UseParallelGC(年轻代)和-XX:+UseParallelOldGC(老年代),如果内存较大(超过4个G,只是经验值),系统对停顿时间比较敏感,我们可以使用ParNew+CMS(-XX:+UseParNewGC -XX:+UseConcMarkSweepGC)
对于碎片整理,因为都是1小时或几小时才做一次FullGC,是可以每做完一次就开始碎片整理,或者两到三次之后再做一次也行。
-XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly
- GC参数
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/demo-api/logs/demo-api/
总而言之,JVM调优不是一蹴而就的,需要各种评估、分析以及尝试。最终线上服务启动参数配置如下
java -XX:+UseContainerSupport -XX:MaxRAMPercentage=60.0 -XX:InitialRAMPercentage=60.0 -XX:MinRAMPercentage=60.0 -XX:NewRatio=2 -Xss512k -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=512M -Djava.awt.headless=true -d64 -server -Djava.awt.headless=true -Djava.net.preferIPv4Stack=true -Djavax.servlet.request.encoding=UTF-8 -Dfile.encoding=UTF-8 -XX:+AlwaysPreTouch -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/demo-api/logs/demo-api/ -jar demo-api-1.0.1-RELEASE.jar --server.port=8080 --management.server.port=8070 --apollo.meta=http://configserver:8080
# 二、线上问题分析记录
# 1、系统频繁Full GC导致系统卡顿
JVM参数设置
-Xms1536M -Xmx1536M -Xmn512M -Xss256K -XX:SurvivorRatio=6 -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly1
2JVM运行情况预估
年轻代对象增长的速率
Young GC的触发频率和每次耗时(YGCT/YGC )
Full GC的触发频率和每次耗时(FGCT/FGC )
初步判定对象动态年龄判断机制,年轻代适当调大点
-Xms1536M -Xmx1536M -Xmn1024M -Xss256K -XX:SurvivorRatio=6 -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=92 -XX:+UseCMSInitiatingOccupancyOnly1
2发现问题:full gc的次数比minor gc的次数还多了
1、元空间不够导致的多余full gc
2、显示调用System.gc()造成多余的full gc,这种一般线上尽量通过-XX:+DisableExplicitGC参数禁用,如果加上了这个JVM启动参数,那么代码中调用System.gc()没有任何效果
3、老年代空间分配担保机制
jmap命令大概看下是什么对象
1、代码里全文搜索生成User对象的地方(适合只有少数几处地方的情况)
2、定位cpu使用较高的代码
# 2、数据库连接池 Druid导致的GC
问题描述:Full GC耗时长(6-7s),频率高(1小时一次)
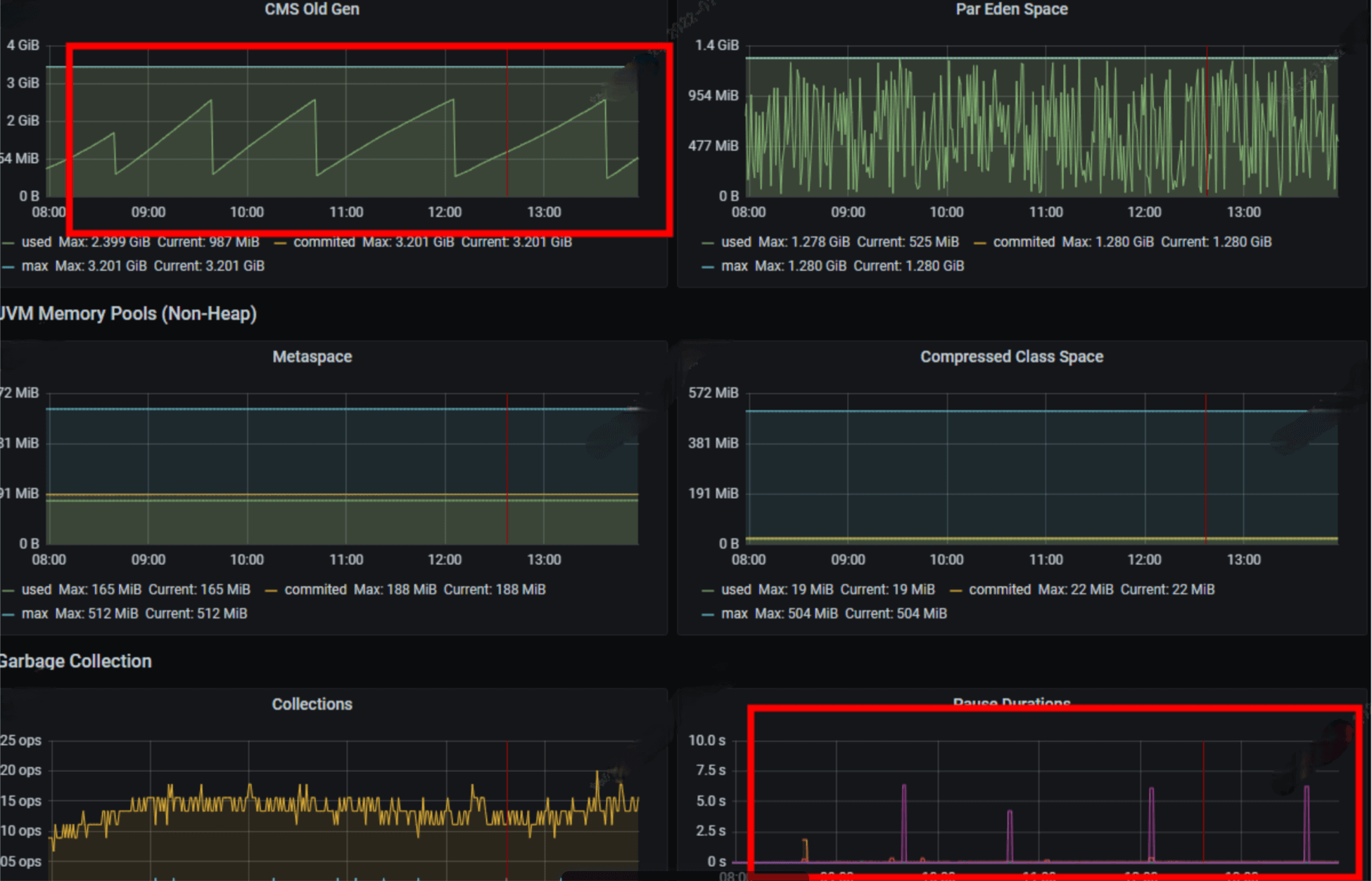
问题分析:使用 jmap 命令 dump 内存快照,使用 mat工具 对快照进行分析
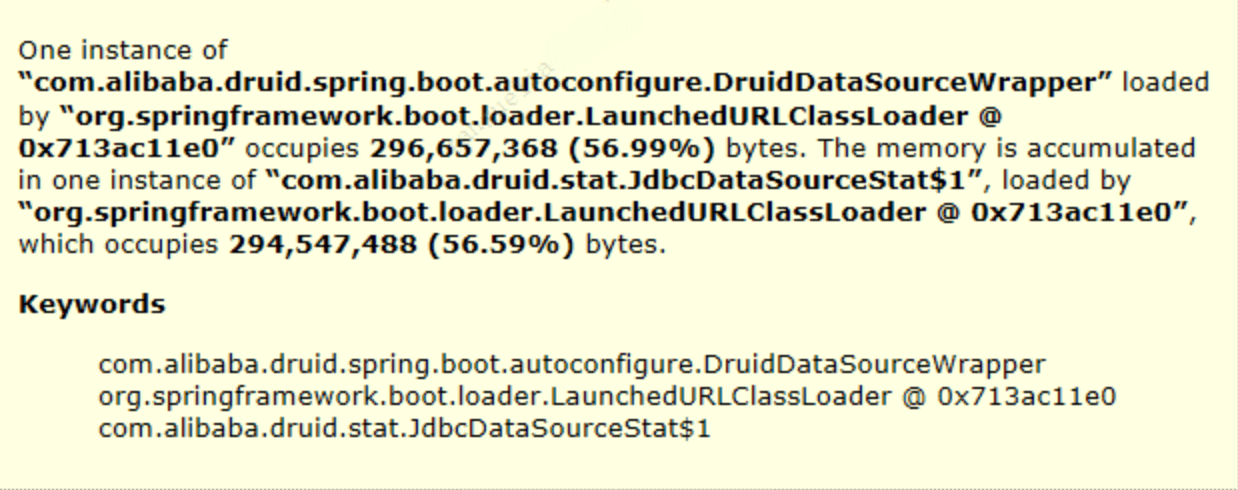
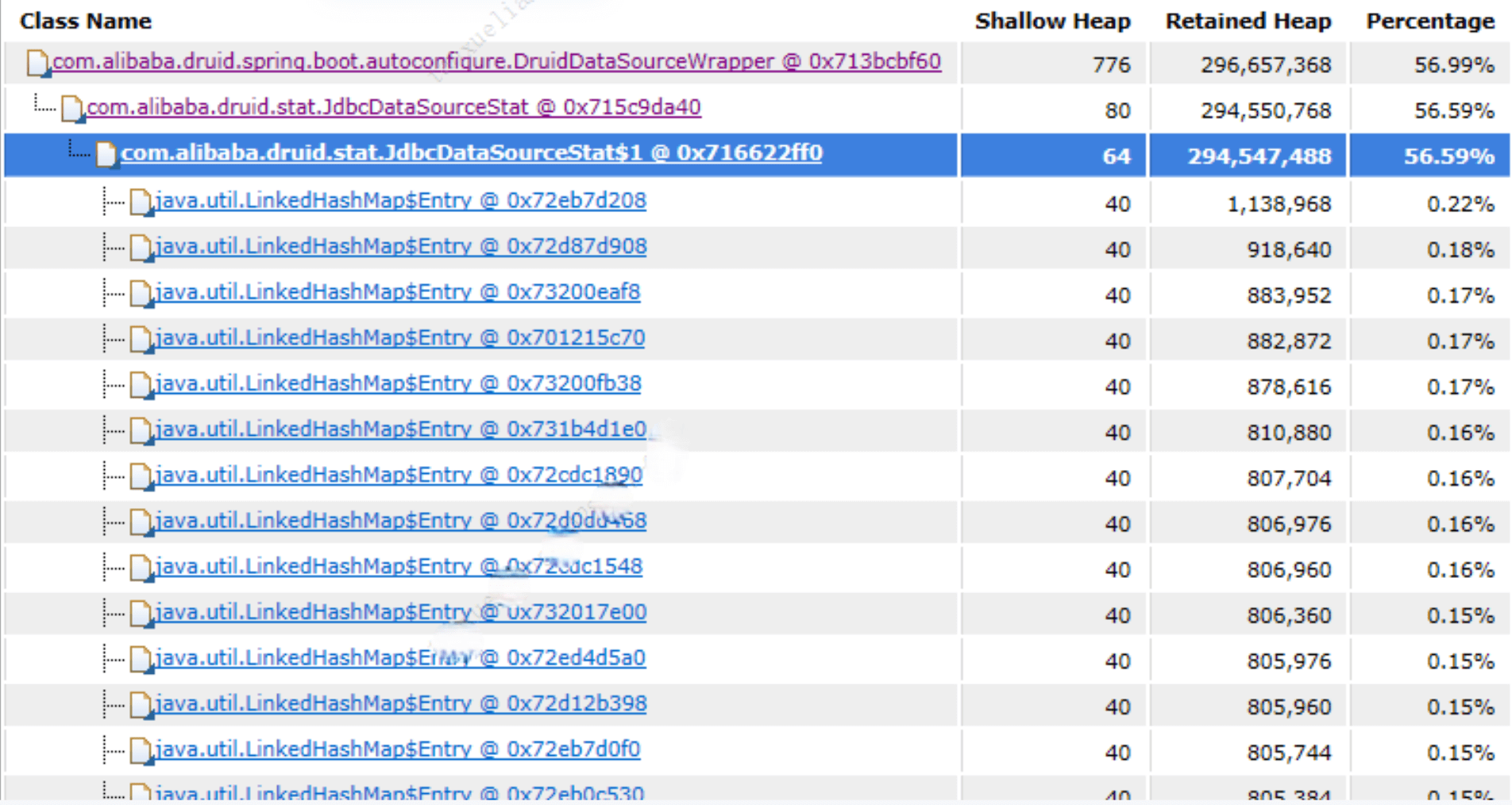
通过分析发现数据库连接池 com.alibaba.druid.stat.JdbcDataSourceStat 中的Retained Heap占比较高,进一步查看发现了大量begin ... end 之类 sql
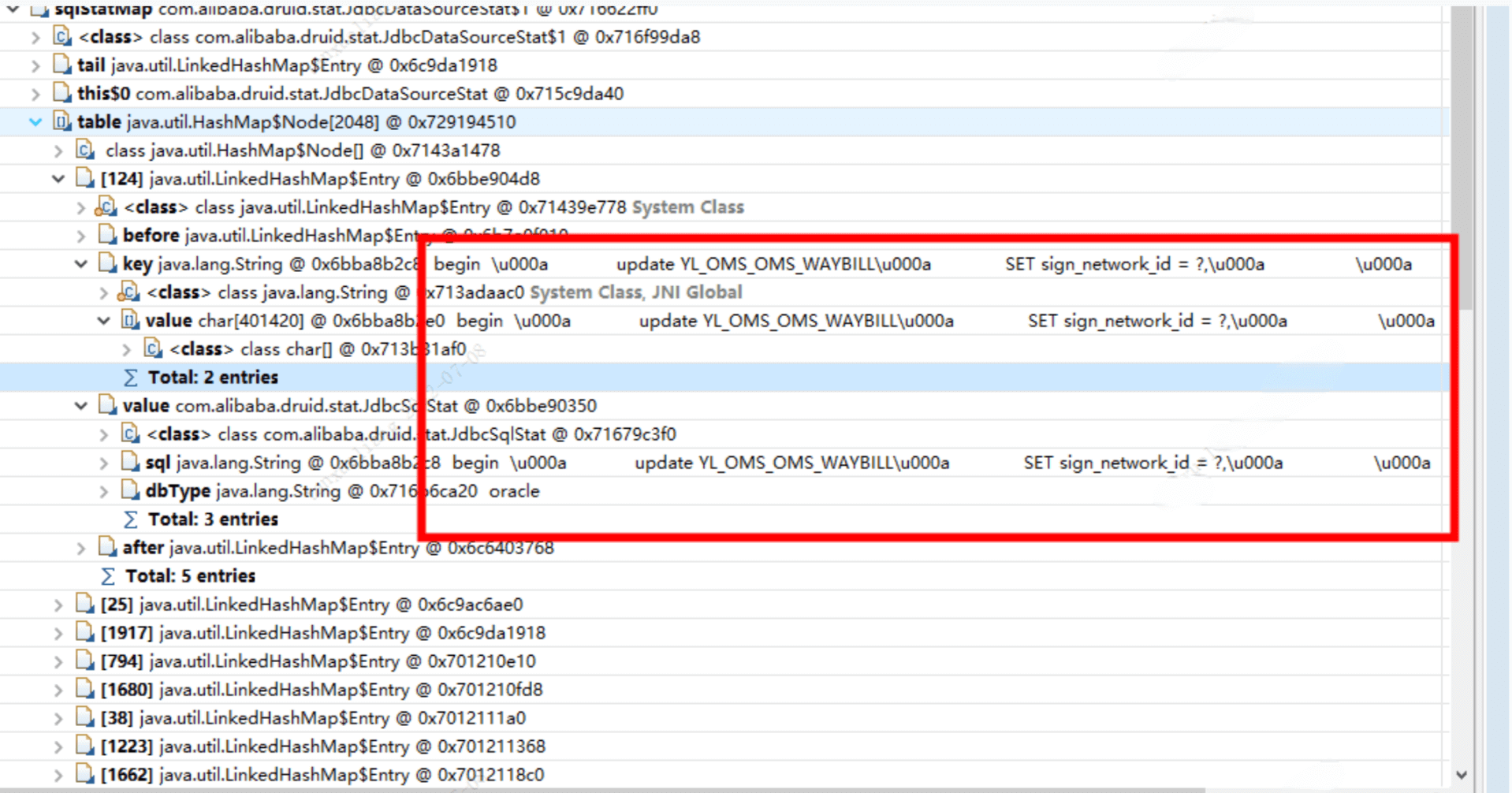
问题定位: druid-spring-boot-starter 中默认启用 *StatFilter,*会统计SQL的执行情况,而在此项目中由于使用oracle begin ... end 块状语句,调用参数不同,执行的SQL的模板也不一样,导致 sqlStatMap 数据过多,内存增长,最终触发 Full GC
解决方案:禁用stat配置即可
spring.datasource.druid.filter.stat.enabled = false
优化效果:Full GC耗时降低(几百毫秒),频率降低(一周)