
 MySQL的存储引擎和索引结构
MySQL的存储引擎和索引结构
# MySQL的存储引擎和索引结构
# 一、简介
MySQL官方对索引的定义是:索引(Index)是帮助MySQL高效获取数据的数据结构。
在MySQL中索引是在存储引擎层实现的,而不是在服务器层实现的,所以不同存储引擎具有不同的索引类型和实现
# 二、存储引擎
# 2.1、MyISAM
MyISAM [maiˈzæm] 的索引文件和数据文件是分离的,叶子节点中存放数据地址。
文件结构如下:
.frm 表定义文件
.myi 索引文件
.myd 数据文件
# 2.2、InnoDB
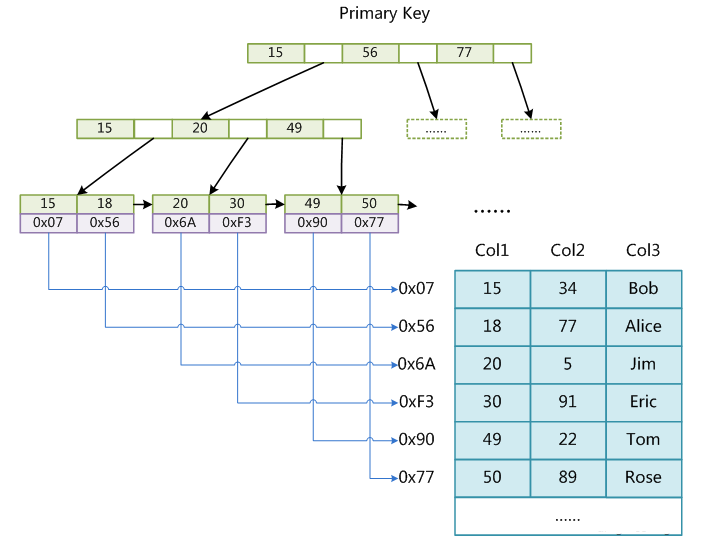
InnoDB表必须要有聚集索引,默认在主键字段上建立聚集索引,在没有主键字段的情况下,表的第一个非空的唯一索引将被建立为聚集索引,在前两者都没有的情况下,InnoDB将自动生成一个隐藏的自增id列,并在此列上建立聚集索引。
文件结构如下:
.frm 表定义文件
.ibd 索引数据文件
# 三、索引分类
# 3.1、按数据结构分类
MySQL索引按数据结构分类可分为:B+tree索引、Hash索引、Full-text索引
1、B+tree索引
a. 非叶子节点上不存储行记录,仅存索引;这就使得非叶子节点上可以存储更多的键值,相应的树的阶数(节点的子节点树)就会更大,树也就会变得更矮更胖。这样一来我们查找数据进行磁盘I/O的次数就会大大减少,数据查询的效率也会更快。
b. 叶子节点上有序存储行记录,通过链表链接,支持范围查询。
一次磁盘IO读取一页数据,一页数据大小为16KB,假设非叶子结点每个索引字段 8字节+4字节,每页大概可以放1100条数据,叶子结点每条数据占1K,每页大概可以放16条数据。一个高度为3的 B+tree 可以存放近2kw条数据,只需要经过三次磁盘IO,另外在一些版本的数据库,根结点/非叶子结点会常驻内存,数据的查询效率非常快
这也是为什么不建议在表记录上有大字段
2、Hash索引
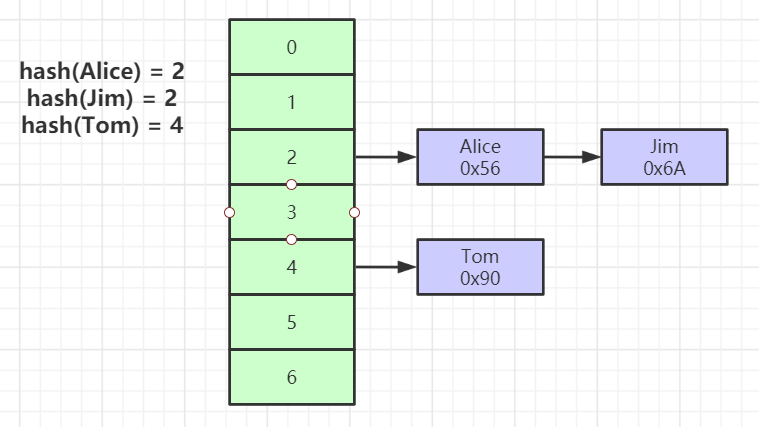
Hash索引在精确查询时的效率要远高于B+Tree索引,但是也存在一些明显的问题:
Hash索引仅仅能满足等值查询,不能进行范围查询
Hash索引无法通过操作索引来排序
组合Hash索引不能利用部分索引键进行查询
Hash索引依然需要回表扫描
3、Full-text索引
Full-text索引一般使用倒排索引实现
# 3.2、按物理存储分类
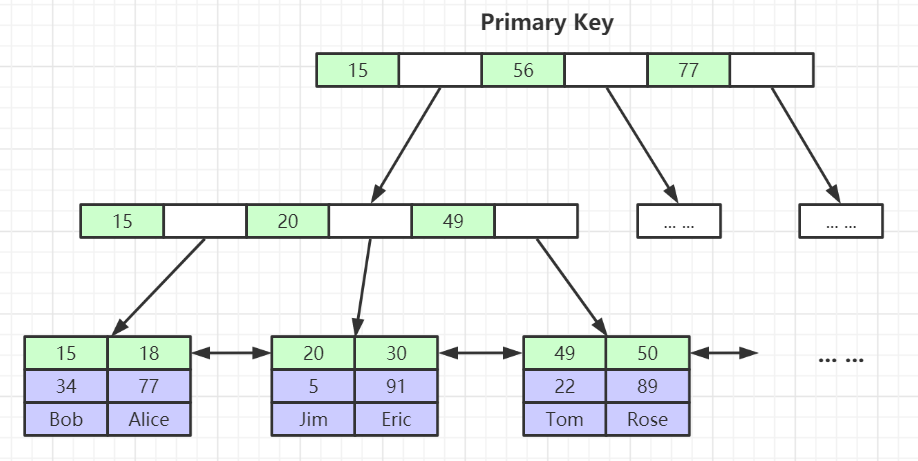
1、聚集索引
聚簇索引就是按照每张表的主键构造 B+tree,叶子节点中存放表的数据记录,聚集索引的叶子节点被称为数据页
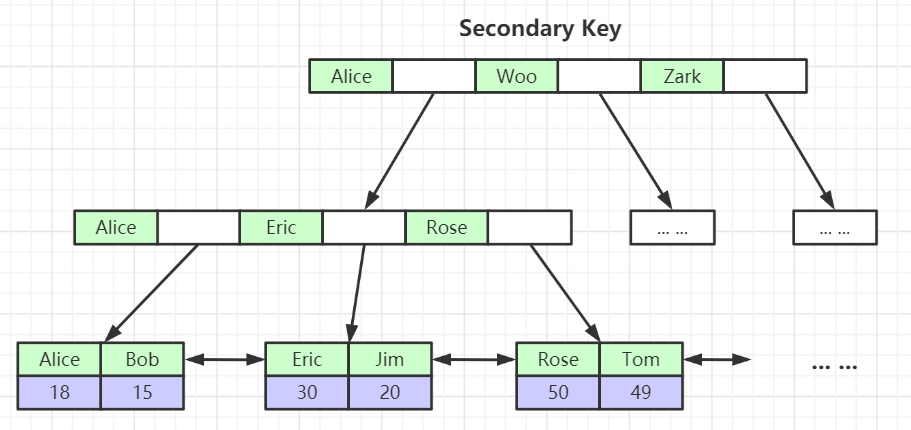
2、非聚集索引(二级索引)
非聚集索引的结构和聚集索引基本相同(非叶子结点存储的都是索引指针),区别在于叶子节点存放的是数据主键而不是行数据。因此在使用非聚集索引进行查找时,需要先查找到主键值,然后再到聚集索引中进行查找。
两种索引的区别:
1、聚集索引的叶子结点包含行记录数据,而非聚集索引的叶子结点只包含主键字段。
2、聚集索引一个表只能有一个,而非聚集索引一个表可以存在多个。
什么是索引覆盖?
索引覆盖就是指索引的叶子节点已经包含了要查询的数据,没必要再回表查询。常见的方式就是建立联合索引(组合索引),实现索引覆盖,从而避免回表查询。
# 3.3、按字段特性分类
MySQL索引按字段特性分类可分为:主键索引(PRIMARY KEY)、唯一索引(UNIQUE)、普通索引(INDEX)、全文索引(FULLTEXT)。
1、主键索引(PRIMARY KEY)
建立在主键上的索引被称为主键索引,一张数据表只能有一个主键索引,索引列值不允许有空值,通常在创建表时一起创建。
2、唯一索引(UNIQUE)
建立在UNIQUE字段上的索引被称为唯一索引,一张表可以有多个唯一索引,索引列值允许为空,列值中出现多个空值不会发生重复冲突。
3、普通索引(INDEX)
建立在普通字段上的索引被称为普通索引。
4、全文索引(FULLTEXT)
MyISAM 存储引擎支持Full-text索引,用于查找文本中的关键词,而不是直接比较是否相等。Full-text索引一般使用倒排索引实现,它记录着关键词到其所在文档的映射。
InnoDB 存储引擎在 MySQL 5.6.4 版本中也开始支持Full-text索引。
# 3.4、按字段个数分类
MySQL索引按字段个数分类可分为:单列索引、联合索引(也叫复合索引、组合索引)。
1、单列索引
建立在单个列上的索引被称为单列索引。
2、联合索引(复合索引、组合索引)
建立在多个列上的索引被称为联合索引,又叫复合索引、组合索引。
在MySQL中使用联合索引时要遵循最左前缀匹配原则。
所以我们需要注意如下几个方面:
a. 实际业务场景中创建联合索引时,我们应该把识别度比较高的字段放在前面,提高索引的命中率,充分的利用索引。
b. 创建联合索引后,该索引的任何最左前缀都可以用于查询。比如当你有一个联合索引(col1, col2, col3),该索引的所有最左前缀为(col1)、(col1, col2)、(col1, col2, col3),包含这些列的所有查询都会使用该索引进行查询。
c. 虽然联合索引可以避免回表查询,提高查询速度,但同时也会降低表数据更新的速度。因为联合索引列更新时,MySQL不仅要保存数据,还要维护一下索引文件。所以不要盲目使用,应根据业务需求来创建。
# 四、常见问题
# 4.1、InnoDB和MyISAM的区别
- InnoDB支持事务,MyISAM不支持
- InnoDB支持行锁,而MyISAM不支持
- InnoDB支持外键,而MyISAM不支持
- InnoDB是聚集索引,数据文件和索引文件在一起的,而MyISAM是非聚集索引,数据文件是分离的
- InnoDB不存储表的行数,而MyISAM会存放表的行数
# 4.2、为什么建议InnoDB表要有主键,并且推荐使用整型的自增主键?
1、若无主键,MySQL帮你维护一个隐藏列,MySQL资源珍贵,请自行维护
2、使用整型是因为整型占用空间小,比较速度快
3、使用自增是为了避免页分裂
# 4.3、为什么非主键索引叶子节点存储的是主键值?
一致性和节省存储空间
参考资料:
https://blog.csdn.net/u013635487/article/details/122469255