
 JVM垃圾收集器二:CMS与三色标记算法详解
JVM垃圾收集器二:CMS与三色标记算法详解
# JVM垃圾收集器二:CMS与三色标记算法详解
# 一、简介
CMS(Concurrent Mark Sweep)是一种以获取最短回收停顿时间为目标的老年代收集器(提高用户体验)。
它的主要特点为并发收集、低停顿,但是也存在几个明显的缺点:
1、CPU资源竞争问题
gc线程是和用户线程并行的,会存在CPU资源竞争
2、浮动垃圾问题
在并发标记和并发清理阶段产生的浮动垃圾只能等到下一次gc再进行清理
3、空间碎片问题
标记清除后会产生大量不连续的空间碎片,通过参数-XX:+UseCMSCompactAtFullCollection优化
4、concurrent mode failure问题
在并发标记和并行清理的过程中,如果老年代的空间不足以容纳应用产生的对象,则会抛出concurrent mode failure,此时会退化为Serial Old收集器,通过参数-XX:CMSInitiatingOccupancyFraction优化
# 二、垃圾回收过程
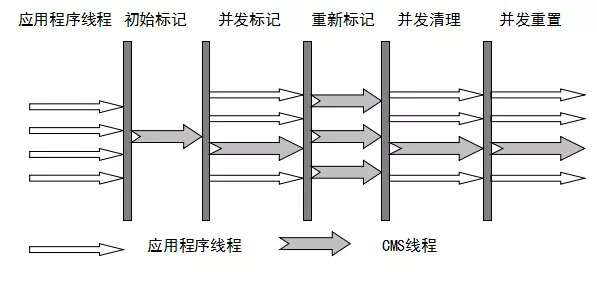
CMS的收集过程主要分为五个阶段:
# 初始标记(STW)
标记
gc roots能直接引用的对象,速度很快# 并发标记
并发标记是遍历对象图做可达性分析的阶段,已经标记过的对象状态可能发生改变(GC线程和用户线程并行)。
# 重新标记(STW)
重新标记就是为了修正并发标记期间,因为用户线程运行而导致标记产生变动的 那一部分对象的标记记录。主要使用了三色标记里的增量更新算法(见下面详解)
# 并发清理
开启用户线程,同时GC线程开始对未标记的区域做清理。在这个阶段新增的对象会被标记为黑色不做任何处理
# 并发重置
重置本次GC过程中的标记数据
# 三、CMS的核心参数详解
-XX:+UseConcMarkSweepGC:使用CMS收集器-XX:ConcGCThreads:并发的GC线程数-XX:+UseCMSCompactAtFullCollection:FullGC之后做压缩整理(减少碎片)-XX:CMSFullGCsBeforeCompaction:多少次FullGC之后压缩一次,默认是0,代表每次FullGC后都会压缩一次-XX:CMSInitiatingOccupancyFraction: 当老年代使用达到该比例时会触发FullGC(默认是92,这是百分比)-XX:+UseCMSInitiatingOccupancyOnly:只使用设定的回收阈值(-XX:CMSInitiatingOccupancyFraction设定的值),如果不指定,JVM仅在第一次使用设定值,后续则会自动调整-XX:MaxTenuringThreshold:年轻代晋升老年代的最大年龄阈值,CMS默认值为6,G1中默认为15【为啥是15?因为在JVM中,该数值是由四个bit来表示的,所以最大值为1111,转换十进制则为15】-XX:+CMSScavengeBeforeRemark:在CMS GC前启动一次minor gc,降低CMS GC标记阶段(也会对年轻代一起做标记,如果在minor gc就干掉了很多对垃圾对象,标记阶段就会减少一些标记时间)时的开销,一般CMS的GC耗时 80%都在标记阶段-XX:+CMSParallelInitialMarkEnabled:初始标记的时候多线程执行,缩短STW-XX:+CMSParallelRemarkEnabled:重新标记的时候多线程执行,缩短STW;
# 四、三色标记算法
我们先看这样一个代码示例:
/**
* 垃圾收集算法细节之三色标记
* 为了简化例子,代码写法可能不规范,请忽略
*/
public class ThreeColorRemark {
public static void main(String[] args) {
A a = new A();
//开始做并发标记
D d = a.b.d; // 1.读
a.b.d = null; // 2.写
a.d = d; // 3.写
}
}
class A {
B b = new B();
D d = null;
}
class B {
C c = new C();
D d = new D();
}
class C {
}
class D {
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
假如运行完A a = new A();之后,开始垃圾回收。
三色标记算法:根据可达性分析,把从gc roots开始,遍历整个对象图的过程中遇到的对象, 按照“是否访问过”这个条件标记为三种颜色
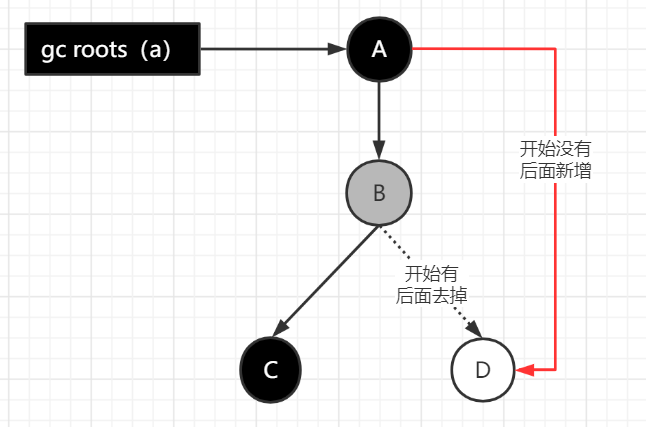
- 黑色 表示对象已经被垃圾收集器访问过, 并且这个对象的所有引用都已经被扫描过
- 灰色 表示对象已经被垃圾收集器访问过, 但是这个对象上至少还存在一个引用还没有被扫描过
- 白色 表示对象没有被垃圾收集器访问过
# 多标问题-浮动垃圾
本应该回收但是没有回收的内存,被称之为“浮动垃圾”。浮动垃圾并不会影响垃圾回收的正确性,只能等到下一次gc再进行清理。浮动垃圾主要分为两部分:
1、在并发标记过程中,由于方法运行结束而导致部分局部变量(gcroot)被销毁,但这个gcroot引用的对象之前又被扫描过(被标记为非垃圾对象),那么本轮GC不会回收这部分内存。
2、在并发标记和并发清理过程中产生的新对象,通常的做法是直接标记为黑色,本轮不会进行清理。这部分对象在这期间也可能会变为垃圾对象
# 漏标问题(读写屏障解决)
漏标会导致被引用的对象被当成垃圾误删除,这有两种解决方案
原始快照(Snapshot At The Beginning,SATB)
当灰色对象要删除指向白色对象的引用关系时, 就将这个要删除的引用记录下来, 等并发扫描结束之后, 再将这些记录过的引用关系中的灰色对象为根, 重新扫描一次,这样就能扫描到白色的对象,将白色对象直接标记为黑色(目的就是让这种对象在本轮gc清理中能存活下来,待下一轮gc的时候重新扫描,这个对象也有可能是浮动垃圾)
增量更新(Incremental Update)
当黑色对象要插入新的指向白色对象的引用关系时, 就将这个要插入的引用记录下来, 等并发扫描结束之后, 再将这些记录过的引用关系中的黑色对象为根, 重新扫描一次。 这可以简化理解为, 黑色对象一旦新插入了指向白色对象的引用之后, 它就变回灰色对象了
那么为什么G1用SATB?CMS用增量更新?
- CMS:写屏障 + 增量更新
- G1,Shenandoah:写屏障 + SATB
- ZGC:读屏障
我们从两方面来进行分析:
1、从扫描代价上来看,增量更新会做深度扫描,但是G1很多对象都位于不同的region,而CMS就一块老年代区域,G1的深度扫描代价会比CMS高
2、从浮动垃圾上来看,尽管SATB可能会产生更多的浮动垃圾,但是SATB相对于增量更新效率更高,对于G1这种大内存的收集器而言,在收集过程中本身就存在很多浮动垃圾。
# 五、其它
# 1. 读写屏障
# 1.1 写屏障
给某个对象的成员变量赋值时,其底层代码大概长这样:
/**
* @param field 某对象的成员变量,如 a.b.d
* @param new_value 新值,如 null
*/
void oop_field_store(oop* field, oop new_value) {
*field = new_value; // 赋值操作
}
2
3
4
5
6
7
所谓的写屏障,其实就是在赋值操作前后,加入一些处理(可以参考AOP的概念):
void oop_field_store(oop* field, oop new_value) {
pre_write_barrier(field); // 写屏障-写前操作
*field = new_value;
post_write_barrier(field, value); // 写屏障-写后操作
}
2
3
4
5
- 写屏障实现SATB
当对象B的成员变量的引用发生变化时,比如删除引用(a.b.d = null),我们可以利用写屏障-写前操作,将对象B要删除的成员变量引用对象D记录下来:
void pre_write_barrier(oop* field) {
oop old_value = *field; // 获取旧值
remark_set.add(old_value); // 记录原来的引用对象
}
2
3
4
- 写屏障实现增量更新
当对象A的成员变量的引用发生变化时,比如新增引用(a.d = d),我们可以利用写屏障-写后操作,将对象A要新增的成员变量引用对象D记录下来:
void post_write_barrier(oop* field, oop new_value) {
remark_set.add(new_value); // 记录新引用的对象
}
2
3
# 1.2 读屏障
oop oop_field_load(oop* field) {
pre_load_barrier(field); // 读屏障-读取前操作
return *field;
}
2
3
4
读屏障是直接针对第一步:D d = a.b.d,当读取成员变量时,一律记录下来:
void pre_load_barrier(oop* field) {
oop old_value = *field;
remark_set.add(old_value); // 记录读取到的对象
}
2
3
4
# 2 记忆集和卡表
记忆集解决了跨代引用的问题。在新生代做可达性分析过程中可能会碰到跨代引用的对象,这种如果再对老年代进行扫描效率太低了。
为此,在新生代引入了记忆集(Remember Set)的数据结构(记录从非收集区到收集区的指针集合),避免把整个老年代加入GCRoots扫描范围。
Hotspot使用一种叫做“卡表”(Cardtable)的方式实现记忆集。关于卡表与记忆集的关系, 可以类比Java语言中HashMap与Map的关系。
卡表使用一个字节数组来实现:CARD_TABLE[ ],每个元素对应着其标识的内存区域一块特定大小的内存块,称为“卡页”。
Hotspot使用的卡页是2^9大小,即512字节
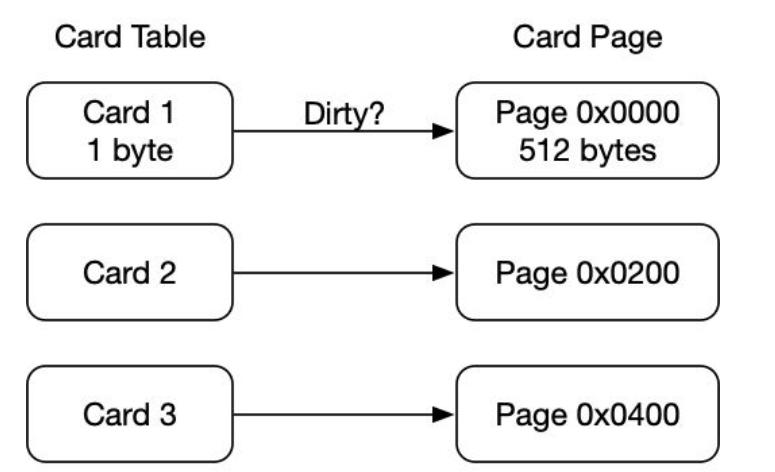
一个卡页中可以包含多个对象,只要有一个对象的字段存在跨代指针,那么其对应的卡表的元素标识就变成1,表示该元素变脏,否则为0.
GC时,只要筛选本收集区的卡表中变脏的元素加入GCRoots里。
卡表的维护
Hotspot使用写屏障维护卡表状态,即发生引用字段赋值时,判断是否更新卡表的标识为1。
# 3 安全点和安全区域
安全点是指代码中一些特定的位置,当线程运行到这些位置时它的状态是确定的,这样JVM就可以安全的进行一些操作,比如GC等,所以GC不是想什么时候做就立即触发的,而是需要等待所有线程运行到安全点后才能触发。
这些特定的位置主要有以下几种:
- 调用某个方法之后
- 方法返回之前
- 抛出异常的位置
- 循环的末尾
大体实现思想是当垃圾收集需要中断线程的时候, 不直接对线程操作, 仅仅简单地设置一个标志位, 各个线程执行过程时会不停地主动去轮询这个标志, 一旦发现中断标志为真时就自己在最近的安全点上主动中断挂起。 轮询标志的地方和安全点是重合的。
安全区域又是什么?
Safe Point 是对正在执行的线程设定的。
如果一个线程处于 Sleep 或中断状态,那么它就不能响应 JVM 的中断请求,无法运行到 Safe Point 上。
因此 JVM 引入了 Safe Region。
Safe Region 是指在一段代码片段中,引用关系不会发生变化。在这个区域内的任意地方开始GC都是安全的。
STW后,其它线程都暂停,安全区域也是安全的。