
 ShardingJDBC读写分离与分库分表实战
ShardingJDBC读写分离与分库分表实战
# 一、读写分离实战
# 1.1、 引入Maven依赖
<properties>
<java.version>1.8</java.version>
<sharding-sphere.version>4.0.0-RC1</sharding-sphere.version>
</properties>
<!-- 依赖web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- 依赖mybatis和mysql驱动 -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.4</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!--依赖lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--依赖sharding-->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-core-common</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
<!--依赖数据源druid-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.21</version>
</dependency>
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
# 1.2、 配置application.yml
server:
port: 8085
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
# 参数配置,显示sql
props:
sql:
show: true
# 配置数据源
datasource:
# 给每个数据源取别名,下面的ds1,ds2,ds3任意取名字
names: ds1,ds2,ds3
# 给master-ds1每个数据源配置数据库连接信息
ds1:
# 配置druid数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://xx.xx.xx.xx:3306/tmp-sharding-db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: xxxxxxxxxxx
maxPoolSize: 100
minPoolSize: 5
# 配置ds2-slave
ds2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://xx.xx.xx.xx:3306/tmp-sharding-db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: xxxxxxxxxxx
maxPoolSize: 100
minPoolSize: 5
# 配置ds3-slave
ds3:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://xx.xx.xx.xx:3306/tmp-sharding-db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: xxxxxxxxxxx
maxPoolSize: 100
minPoolSize: 5
# 配置默认数据源ds1
sharding:
# 默认数据源,主要用于写,注意一定要配置读写分离 ,注意:如果不配置,那么就会把三个节点都当做从slave节点,新增,修改和删除会出错。
default-data-source-name: ds1
# 配置数据源的读写分离,但是数据库一定要做主从复制
masterslave:
# 配置主从名称,可以任意取名字
name: ms
# 配置主库master,负责数据的写入
master-data-source-name: ds1
# 配置从库slave节点
slave-data-source-names: ds2,ds3
# 配置slave节点的负载均衡均衡策略,采用轮询机制
load-balance-algorithm-type: round_robin
# 整合mybatis的配置XXXXX
mybatis:
mapper-locations: classpath:mapper/*.xml
type-aliases-package: com.ruanyou.shardingjdbc.entity
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
注意问题:
# 配置默认数据源ds1 sharding: # 默认数据源,主要用于写,注意一定要配置读写分离 # 注意:如果不配置,那么就会把三个节点都当做从slave节点,新增,修改和删除会出错。 default-data-source-name: ds1 # 配置数据源的读写分离,但是数据库一定要做主从复制 masterslave: # 配置主从名称,可以任意取名字 name: ms # 配置主库master,负责数据的写入 master-data-source-name: ds1 # 配置从库slave节点 slave-data-source-names: ds2,ds3 # 配置slave节点的负载均衡均衡策略,采用轮询机制 load-balance-algorithm-type: round_robin1
2
3
4
5
6
7
8
9
10
11
12
13
14
15如果上面的,那么shardingjdbc会采用随机的方式进行选择数据源。
# 1.3、 定义mapper、controller,entity
entity
package com.ruanyou.shardingjdbc.entity;
import lombok.Data;
@Data
public class User {
// 主键
private Integer id;
// 昵称
private String nickname;
// 密码
private String password;
// 性
private Integer sex;
// 性
private String birthday;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2
3
4
5
6
7
8
9
10
11
12
13
14
15
mapper
package com.ruanyou.shardingjdbc.mapper;
import com.ruanyou.shardingjdbc.entity.User;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
import java.util.List;
public interface UserMapper {
@Insert("insert into tmp-user(nickname,password,sex,birthday) values(#{nickname},#{password},#{sex},#{birthday})")
void addUser(User user);
@Select("select * from tmp-user")
List<User> findUsers();
}
1
2
3
4
5
6
7
8
9
10
11
12
13
2
3
4
5
6
7
8
9
10
11
12
13
controller
package com.ruanyou.shardingjdbc.controller;
import com.ruanyou.shardingjdbc.entity.User;
import com.ruanyou.shardingjdbc.mapper.UserMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
import java.util.Random;
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserMapper userMapper;
@GetMapping("/save")
public String insert() {
User user = new User();
user.setNickname("zhangsan"+ new Random().nextInt());
user.setPassword("1234567");
user.setSex(1);
user.setBirthday("1988-12-03");
userMapper.addUser(user);
return "success";
}
@GetMapping("/listuser")
public List<User> listuser() {
return userMapper.findUsers();
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 1.4、 访问测试查看效果
1:访问 http://localhost:8085/user/save 一直进入到ds1主节点
2:访问 http://localhost:8085/user/listuser 一直进入到ds2、ds3节点,并且轮询进入。
# 1.5、 日志查看


# 二、分库分表实战
# 2.1、分库分表的方式
水平拆分:统一个表的数据拆到不同的库不同的表中。可以根据时间、地区、或某个业务键维度,也可以通过hash进行拆分,最后通过路由访问到具体的数据。拆分后的每个表结构保持一致。
垂直拆分:就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。每个库表的结构都不一样,每个库表都包含部分字段。一般来说,可以根据业务维度进行拆分,如订单表可以拆分为订单、订单支持、订单地址、订单商品、订单扩展等表;也可以,根据数据冷热程度拆分,20%的热点字段拆到一个表,80%的冷字段拆到另外一个表。
# 2.2、分库分表的配置
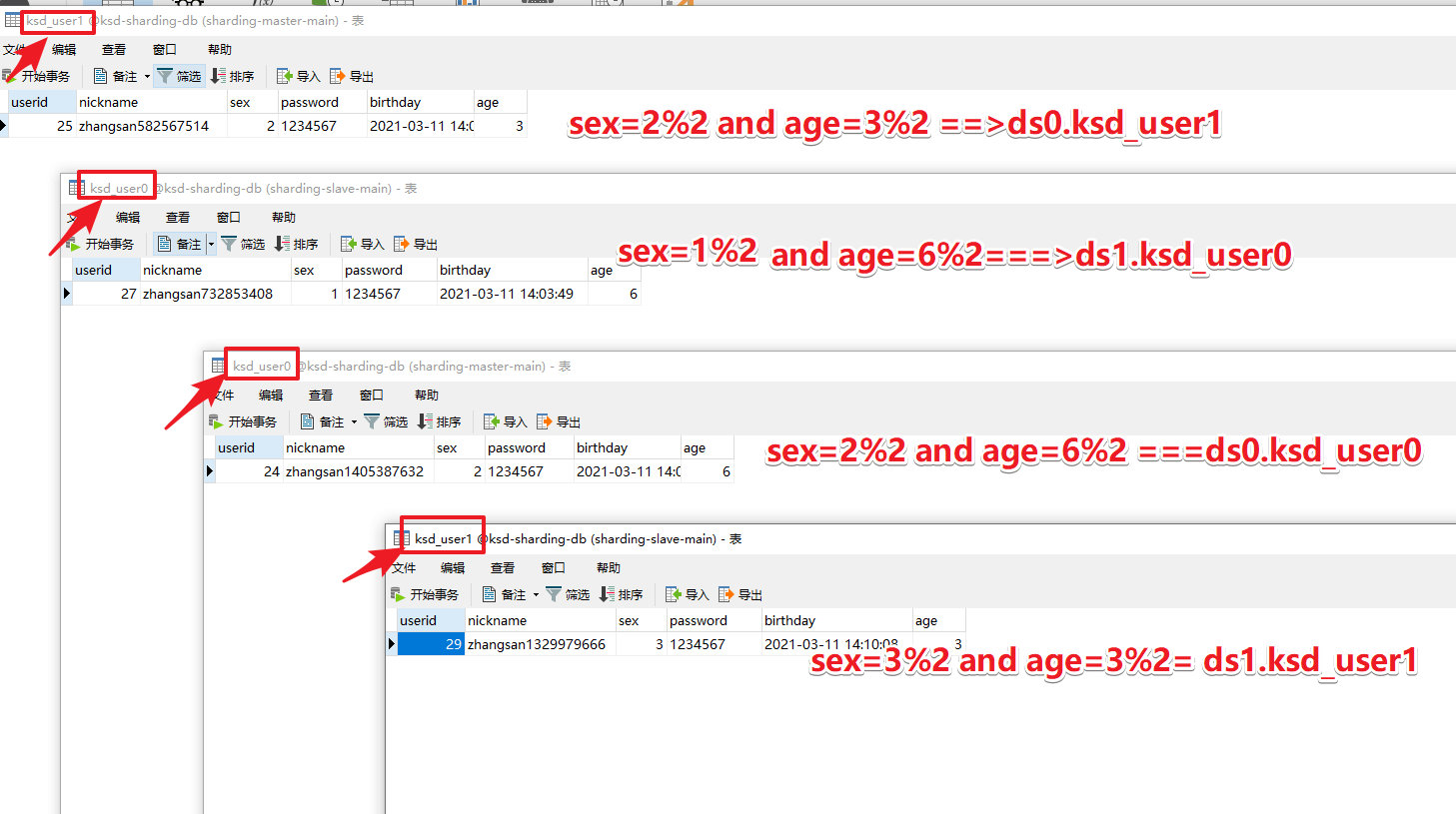
- 准备两个数据库tmp-sharding-db。名字相同,两个数据源ds0和ds1
- 每个数据库下方tmp-user0和tmp-user1即可。
- 数据库规则,性别为偶数的放入ds0库,奇数的放入ds1库。
- 数据表规则:年龄为偶数的放入tmp-user0库,奇数的放入tmp-user1库。
server:
port: 8085
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
# 参数配置,显示sql
props:
sql:
show: true
# 配置数据源
datasource:
# 给每个数据源取别名,下面的ds1,ds1任意取名字
names: ds0,ds1
# 给master-ds1每个数据源配置数据库连接信息
ds0:
# 配置druid数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://47.115.94.78:3306/tmp-sharding-db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: xxxxxxxxxxx
maxPoolSize: 100
minPoolSize: 5
# 配置ds1-slave
ds1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://114.215.145.201:3306/tmp-sharding-db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: xxxxxxxxxxx
maxPoolSize: 100
minPoolSize: 5
# 配置默认数据源ds0
sharding:
# 默认数据源,主要用于写,注意一定要配置读写分离 ,注意:如果不配置,那么就会把三个节点都当做从slave节点,新增,修改和删除会出错。
default-data-source-name: ds0
# 配置分表的规则
tables:
# tmp-user 逻辑表名
tmp-user:
# 数据节点:数据源$->{0..N}.逻辑表名$->{0..N}
actual-data-nodes: ds$->{0..1}.tmp-user$->{0..1}
# 拆分库策略,也就是什么样子的数据放入放到哪个数据库中。
database-strategy:
inline:
sharding-column: sex # 分片字段(分片键)
algorithm-expression: ds$->{sex % 2} # 分片算法表达式
# 拆分表策略,也就是什么样子的数据放入放到哪个数据表中。
table-strategy:
inline:
sharding-column: age # 分片字段(分片键)
algorithm-expression: tmp-user$->{age % 2} # 分片算法表达式
# 整合mybatis的配置XXXXX
mybatis:
mapper-locations: classpath:mapper/*.xml
type-aliases-package: com.ruanyou.shardingjdbc.entity
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
结果如下图:
# 三、分库分表问题处理
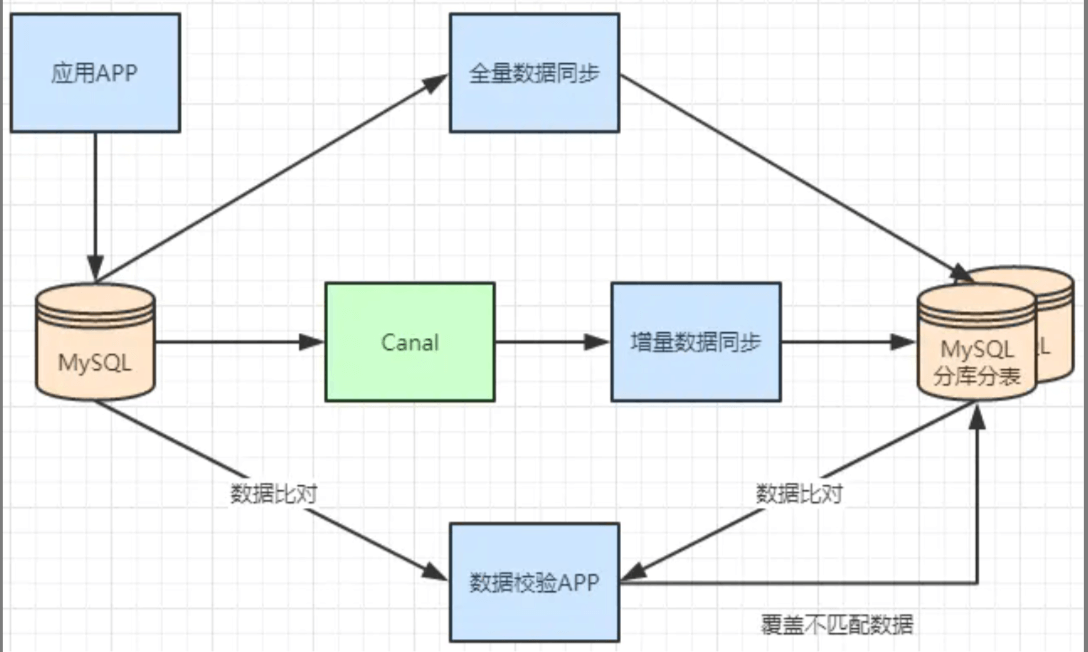
# 3.1、不停机分库分表数据迁移
一般数据库的拆分也是有一个过程的,一开始是单表,后面慢慢拆成多表。那么我们就看下如何平滑的从MySQL单表过度到MySQL的分库分表架构。 1、利用mysql+canal做增量数据同步,利用分库分表中间件,将数据路由到对应的新表中。 2、利用分库分表中间件,全量数据导入到对应的新表中。 3、通过单表数据和分库分表数据两两比较,更新不匹配的数据到新表中。 4、数据稳定后,将单表的配置切换到分库分表配置上。
# 3.2、如何让同一个用户的订单都在一个表中?
也就是分库分表后满足两点
1、同一个客户的订单,需要放到同一个表中
2、根据订单号,需要知道这个订单在哪个中
可以这样实现:
订单id: 使用雪花算法生成 + 客户id的后2位
分片策略:截取订单id后两位来进行分片