
 一条SQL的平凡之路--执行篇
一条SQL的平凡之路--执行篇
# 一条SQL的平凡之路--执行篇
# 一、一条SQL的完整执行过程
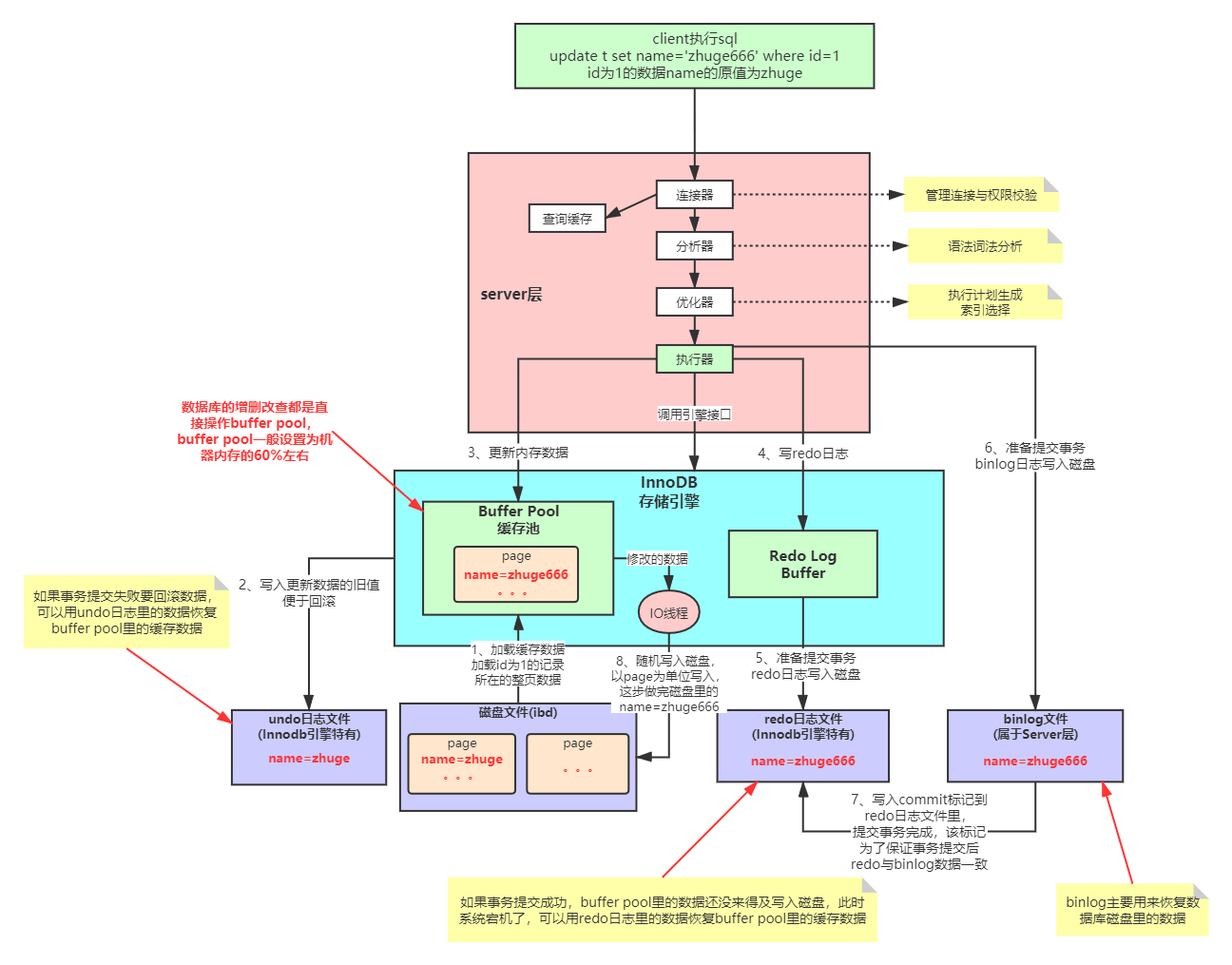
我们将MySQL分为三部分,客户端、服务端、存储引擎。当我们执行upate t set name = 'xxxx' where id = 1这样一条语句,整体过程大致如下:
1、客户端会向服务端发起连接,请求执行SQL
2、服务端收到请求后,依次会经过连接器(管理连接和权限校验),分析器(词法语法分析),优化器(执行计划生成与索引选择)、执行器(根据执行计划调用存储引擎的接口)
1>加载id为1的记录所在的整页数据到buffer pool中(数据库的增删改查都是直接操作buffer pool的,一般设置为机器内存的60%左右)
2>将旧数据写入undo日志文件(Innodb引擎特有,如果事务提交失败要回滚数据,可以用undo日志里面的数据恢复buffer pool里的缓存数据)
3>将内存数据id=1的记录name更新为xxxxx
4>redo log buffer中记录redo日志
5>准备提交事务,redo日志写入磁盘
6>准备提交事务,bin日志写入磁盘
7>写入commit标记到redo日志文件里,提交事务完成,该标记为了保证事务提交后redo与binlog数据一致
8>io线程随机写入磁盘,以page为单位写入
为什么Mysql不能直接更新磁盘上的数据而且设置这么一套复杂的机制来执行SQL了?
因为来一个请求就直接对磁盘文件进行随机读写,然后更新磁盘文件里的数据性能可能相当差。因为磁盘随机读写的性能是非常差的,所以直接更新磁盘文件是不能让数据库抗住很高并发的。
Mysql这套机制看起来复杂,但它可以保证每个更新请求都是更新内存BufferPool,然后顺序写日志文件,同时还能
保证各种异常情况下的数据一致性。
更新内存的性能是极高的,然后顺序写磁盘上的日志文件的性能也是非常高的,要远高于随机读写磁盘文件。
正是通过这套机制,才能让我们的MySQL数据库在较高配置的机器上每秒可以抗下几干的读写请求。
# 二、常见问题
# 2.1、undo log、redo log、bin log、relay log
undo log(回滚日志)
是 Innodb 存储引擎层生成的日志,实现了事务中的原子性,主要用于事务回滚和 MVCC
redo log(重做日志)
是 Innodb 存储引擎层生成的日志,实现了事务中的持久性,主要用于故障恢复
bin log (归档日志)
是 Server 层生成的日志,主要用于数据备份和主从复制
relay log(中继日志)
是主从架构中从服务器上的日志,主要用于replay,保持和主服务器一致性